Thanks for asking a good question. (Added attachment)
It is not a simple question. Basically, it is data about data. This book names all Queries, Rules, and tables with a prefix of M_ I prefere R_ (after all, it is half of Rx LOL).
I have picked a few choice quotes, let me know if it answers your question. I read this book over a weekend then modified the architecture to work better with my specific implementation. In the "old days" (i.e. Cold War) we use to actually get very involved in this sort of thing. Since then, I have been very fortunate to apply some of these concepts to Health Care and Environmental applications.
I would bet that most advanced developers actually have a mental model of metadata. A book like this just helps put a face and name to what we often end up doing to solve day-to-day objectives. That said:
Please allow me to quote:
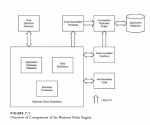
The Business Rules Repository
A repository is a database that stores metadata. Metadata is loosely defined as "data about data." As noted in Chapter 3, this definition is rather poor, but is very widely accepted. Unfortunately, there is not an easy distinction between data and metadata. The reality is that metadata is any data that the user of the system does not manage. In other words, a business application manages a set of data, which would in fact exist in the absence of any computerized system. Metadata exists for this business data, such as definitions of business terms. Again, a lot of this kind of "business" metadata exists even in the absence of a computerized system. This metadata may be needed by staff in order to manipulate the business data, but the metadata is not itself processed. When a computerized application is introduced there is a great deal more metadata to contend with. This new kind of metadata is everything that describes the computerized application and how it works. Again, this metadata may be needed to understand how to run the application, but is not actually processed by the application-or, at least, processing it is not directly relevant to the business area covered by the system. Only the processing of data is relevant to the business area. So very roughly, information that a user needs to manipulate is data, and all the other information that a system stores and manipulates is metadata. The data is stored in the application's database. Metadata is stored in a database that is by convention called a repository.
Application Database Metadata
Perhaps the most fundamental part of the Business Rules Repository is the application database metadata. This is metadata that describes the structure of the application database. A database has a structure that consists primarily of tables containing columns. The business rules engine has to understand this structure so that it can access data in the database and update relevant data as required. There are also relationships between tables. These are extremely important for a rules engine, because they dictate how the database must be navigated. Beyond this, there are more subtle aspects of the application database that are necessary for the rules engine. Subtypes are extremely important. These are subsets of records and columns in a table that behave in a specific way. They are not always recognized as such either in data modeling techniques or in application development. Yet they are critical for rules engines because many business rules apply only to one or a very few subtypes. Closely related to subtypes is the area of reference data. This has been mentioned in earlier chapters and consists of lookup tables such as Country, Customer Type, or Order Status. Reference data tables usually consist of a single primary key column that is a code and a single nonkey column that is a description-for example, a Country Code of "CAN" that goes with a Country Name of "Canada" may be found in a Country table. Reference data tables are primary drivers of business rules because they identify the subtypes that the rules operate on. Up to 50% of the tables in an application database can be reference tables of this kind. Here we see how reference data, which is always considered to be application data, can also be viewed as a kind of metadata, an example of how the boundary between data and metadata can be blurred.
The distinction between metadata and data can get confusing when dealing with business rules engines because a rules engine intimately entwines the two. The type of business rules engine described in this book has at its heart a Business Rules Repository that contains several different kinds of metadata. In the sample application presented here the Business Rules Repository is a set of tables that exists in a single database along with other tables that make up the application database which contains the business data. It may be more appropriate in other circumstances to separate the Business Rules Repository into a distinct database. For instance, there may be a requirement that the Business Rules Repository be a proprietary component of an application, and security can be implemented to prevent unauthorized access to it. In other situations there may be other needs that dictate that the Business Rules Repository and business data must reside in the same single database. In general, from the perspective of the rules engine, either design will work. A convention adopted here is that all tables that belong to the Business Rules Repository have physical names that end with "_M" (for "metadata"). The tables containing business data have different suffixes. This makes it easy to distinguish the tables of the Business Rules Repository in the database of the sample application. Let us now consider the subcomponents. (followed by many, many pages of the gory details... LOL)
Malcolm Chisholm. How to Build a Business Rules Engine: Extending Application Functionality through Metadata Engineering (p. 65). Kindle Edition.