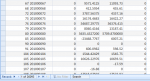
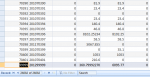
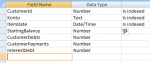
I have a query with just one table in it but with a lot of data in it, more than 6 million. The table contains data from 2006 up to 2018 (no new records are added to it or removed) but I only need from 2012 and above. So I was thinking to make a new table which wont contain anything under 2012. And I did but the gain was just about 15 seconds. The original query with same used criteria takes about 3 minutes, and with the new table 2012 and above just 15 seconds faster.
The table contains amount of payments and amount which he needs to pay. The query returns a field how much every customer owns CustomerDebts and a field how much did he pay CustomerPayments, besides those 2 a CustomerId, CustomerKontoNumber and 2 other fileds which are set to 0 as default.
The Group By is being done on CustomerId, First on CustomerKontoNumber, Expression on the 2 fileds which return 0 and Sum on the 2 fileds CustomerDebts and CustomerPayments.
Here is the actual SQL with criteria (i translated it from another language so its maybe easier to get into it):
The Group By was actually set to this
GROUP BY CLng(Right(CStr([ItemDatabase].[Konto]),5));
and I moved it to GROUP BY ItemDatabase.Konto; which improved the query speed for about 20 seconds (tested on original database, not the one split from 2012)
I use this query later in another query, so I was thinking maybe instead making a query to write this query data to a temp table and use that temp table in the other query later on. However, this doesnt increase the speed of this query Im trying to improve but might help in the second one.
The Analyze performance gave me a tip to change the ItemDatabase.Date to Index and I did but I didnt see any improvement there so I put it back to no index.
Any tips are welcome!
Thanks")
The table contains amount of payments and amount which he needs to pay. The query returns a field how much every customer owns CustomerDebts and a field how much did he pay CustomerPayments, besides those 2 a CustomerId, CustomerKontoNumber and 2 other fileds which are set to 0 as default.
The Group By is being done on CustomerId, First on CustomerKontoNumber, Expression on the 2 fileds which return 0 and Sum on the 2 fileds CustomerDebts and CustomerPayments.
Here is the actual SQL with criteria (i translated it from another language so its maybe easier to get into it):
Code:
SELECT First(CLng(Right(CStr([ItemDatabase].[Konto]),5))) AS CustomerId, ItemDatabase.Konto AS Konto,
0 AS StartingBalance, Sum(ItemDatabase.CustomerDebts) AS CustomerDebts,
Sum(ItemDatabase.CustomerPayments) AS CustomerPayments, 0 AS InterestDebt
FROM ItemDatabase
WHERE (((ItemDatabase.ItemDate)>#1/1/2012# And (ItemDatabase.ItemDate)<[forms]![frmBalanceForming]![txtDateStart])
AND ((Left([Konto],4))='2010' Or (Left([Konto],4))='2011' Or (Left([Konto],4))='2012')
AND (([OrderId] & "/" & [OrderType])<>"1/PS") AND ((ItemDatabase.CustomerDebts)<>0)
AND ((ItemDatabase.ItemType)<>"K")) OR (((ItemDatabase.Date)>#1/1/2012#
And (ItemDatabase.Date)<=[forms]![rmBalanceForming]![txtDateStart])
AND ((Left([Konto],4))='2010' Or (Left([Konto],4))='2011' Or (Left([Konto],4))='2012')
AND (([OrderId] & "/" & [OrderType])<>"1/PS") AND ((ItemDatabase.CustomerPayments)<>0))
GROUP BY ItemDatabase.Konto;The Group By was actually set to this
GROUP BY CLng(Right(CStr([ItemDatabase].[Konto]),5));
and I moved it to GROUP BY ItemDatabase.Konto; which improved the query speed for about 20 seconds (tested on original database, not the one split from 2012)
I use this query later in another query, so I was thinking maybe instead making a query to write this query data to a temp table and use that temp table in the other query later on. However, this doesnt increase the speed of this query Im trying to improve but might help in the second one.
The Analyze performance gave me a tip to change the ItemDatabase.Date to Index and I did but I didnt see any improvement there so I put it back to no index.
Any tips are welcome!
Thanks
Attachments
-
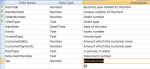 ItemDatabase.PNG16.7 KB · Views: 516
ItemDatabase.PNG16.7 KB · Views: 516
Last edited: