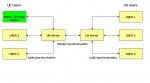
Hello all. I really hope you can help me. I have a replicated database - see attached for its structure.
Just a quick comment. I would never use the DM for production editing, as your diagram appears to inidicate (user 1 on the UK server). The DM should be kept somewhere safe and synched with the replica set only often enough to keep it from expiring. As the default retention period for replicated databases is 1000 days, that doesn't have to be very often -- I generally do it once a month.
Also, your diagram doesn't say what kinds of computers these users are on, but if they are desktops all connected to the same two LANs, then I question why you're using replication at all -- instead, they should all just be using the back end stored on the server for that location. If they are laptops and are editing data in the field, then it all makes perfect sense. If they are workstations connected to a LAN, then I'd suggest that you could entirely eliminate replication from your scenario by setting up a Windows Terminal Server in either the US or UK office and having the other office run the app on Terminal Server. It's very easy and inexpensive to set up (much easier than indirect replication!) and is very fast and reliable (in some cases it can be faster than running the app across a LAN).
Of course, those observations may not apply to your situation, i.e, specifically if your users are on laptops and need to edit the data when not connected to the LAN. Otherwise, you should give consideration to my suggestions above, as it would make life much easier to *not* need replication at all.
Most people have no problem synchronising but I have one user in the US who regularly gets the following error when trying to synchronise with the US Server:
"The field is too small to accept the amount of data you attempted to add. Try inserting or pasting less data".
Yet when I synchronise the design master in the UK directly with her replica over the network it goes through just fine! I really am baffled by this and would appreciate any advice. Is there any way to 'debug' the sychronisation so I can see exactly what is causing it to fail?
Based on extensive Googling that I've just done, I see that this has been a very commonly-encountered replication problem (but one one I've ever encountered myself in my 10 years of replication work), but it doesn't seem to me that there is any particularly good explanation of why it happens. Here are some messages from threads in microsoft.public.access.replication:
http://groups.google.com/group/microsoft.public.access.replication/msg/5fd2b320f05cf42d
http://groups.google.com/group/microsoft.public.access.replication/msg/84d9338e8270e39c
http://groups.google.com/group/microsoft.public.access.replication/msg/d12bfd7b0f6bdfcc
http://groups.google.com/group/microsoft.public.access.replication/msg/b1d5c00daf26f929
http://groups.google.com/group/microsoft.public.access.replication/msg/65afaec8dafbc944
To summarize the discussion represented by those messages cited above:
1. it's obviously not the simple case of a user trying to paste 300 characters into a 255-character field, as if this were the case, the data would never have been saved in the replica in the first place, as the data entry would not have been completed. It's clearly a problem that developed after data was entered by your user and accepted into the replica's data tables.
2. it's possibly a problem caused by a schema change. If you have pre-existing data in replicas and introduce a validation rule before making sure all the records in all your replicas have data that conforms to the new validation rule, you can introduce this class of problems (the correct way to do this is by synching all the replicas and then running a query on the fields you're intending to change in order to update them to values that will be valid for the new validation or referential integrity rules, then synching all the replicas again, and only *then* applying the schema change to the DM and synching with the replica set -- after you know all the data in all the replicas already conforms to the new set of validation/RI rules). But if that were the cause of the error, it would be reported as a schema error. Neither you nor the other folks reporting this problem have said that Jet is reporting a schema or design error, which is what you'd expect if it was caused by a validation rule change or a change in referential integrity. So, I don't think this is likely to be a schema problem. However, do note that it's quite possible for a schema change to cause an error in only one replica if the replica has data in it unique to that replica because it wasn't synched with another replica before the synch that attempts to propagate the schema change.
3. it's not clear if only your back end (i.e., MDB with data tables) is the only thing that is replicated, or if your app is split, or if you've replicated front end objects (forms/reports/etc.). If you aren't split or are replicated your front end, then that's something I'd eliminate immediately, as either is bound to cause unpredictable problems. Rule: Jet Replication works well only for pure Jet objects, which means tables and queries only. That means only a back end MDB with tables alone is going to work well for replication.
4. having eliminated user data entry errors, schema changes and front end replication issues, we are left with one likely candidate: corruption. As you see from reviewing the messages above, that is the conclusion that Michael Kaplan (who is a *real* expert on Jet Replication, though he has moved on to other subjects now) suggested in each case. And it's very likely a memo field corruption problem. As you may know, memo fields can hold up to 64K of data and are not stored inline in the record with the other data fields (if they were, it would make the records exceed the 2000-byte or 4000-byte length limit). Instead, a pointer to a data page elsewhere in the MDB file is all that is stored with the record. These pointers are fragile and can be very easily corrupted. The symptom for this is that when you hit a record with a corrupted memo pointer, the record displays with #ERROR or #DELETED in all the fields or in the memo field only, and often, any operations attempted on that record will cause Access to crash. The only way to correct a corrupted memo field is to copy all the data you can get out of the record and then delete it. You then have to recreate the record from scratch (it's best to do a compact between the deletion and the recreation of the new record).
Some advice on how to do this is here:
http://www.granite.ab.ca/access/corruption/corruptrecords.htm
and:
http://www.mvps.org/access/tables/tbl0018.htm
However, note that those tips don't account for replication. You would not want to completely replace your old table with a new one, and couldn't anyway, unless the corruption were in the Design Master. You would also want to be careful about the implications of deleting records in a replica. I would likely use the code at the first link to locate the problematic records, and then manually copy those records into a temp table with the same structure, delete the problematic records, then append them back to the original table (with a query, so you can maintain the PK). Keep in mind that you may have issues with referential integrity if the table with the corrupt memo field is the parent table in a relationship with a child table. In that case, you'll have to make copies of the child records, too, and delete them manually, or let RI's cascade deletes delete them when you delete the parent records. Also, you have to be careful about the data in the other replicas -- if there are child records in other replicas that don't exist yet in the problem replica, you're going to need to make copies of them before you synch with the problem replica in order that you can restore them after they are deleted (assuming CASCADE DELETE is set on -- if it's off, then you'll need to delete them manually).
Now, what if you run Tony Toews's code to find corrupt memos and you don't find any? Well, that's a different kettle of fish! But, at least you're one step closer to solving it by having eliminated a possible source of the problem.
But if it *is* a memo problem, here are some considerations for preventing memo corruption in replicated databases:
A. In replicas, it's a bad idea to have scheduled synchs take place with a production editing replica *if* the application users textbox controls bound to memo fields. The reason it's a bad idea is that a synch on a record where a user is editing the memo will corrupt the memo pointer and you'll lose the record (as described above). The solution is to edit all memo fields in unbound controls. You do this by removing the control source from your memo textbox on your form, and then use the OnCurrent event to assign the data from the form's recordsource to the unbound textbox:
Me!txtMemo = Me!Memo
Then in the textbox's AfterUpdate event, you'd write the value back:
Me!Memo = Me!txtMemo
Me.Dirty = False
You also have to make sure you immediately save the record after writing the memo value back to the recordsource, because otherwise you've gained nothing by unbinding your textbox! And if you have a SAVE RECORD button on your form, then you need to include Me!Memo = Me!txtMemo in it to make sure the data gets saved.
B. you may also want to move all your memos out of your main table entirely so that any corruption that you have won't cause you to lose other data. If your table has only one memo field, then you'd create a 1:1 table that has only the PK of the main table and your memo field. You can then include this memo table in your form's recordsource as an outer join.
If there are multiple memos, you could create a 1:N table and have the PK field and a field that defines which type of memo it is. You'd then have a unique compound index on those two fields, and then your field for the actual memo data. You'd not be able to include this table in your form's recordsource, but would need a subform to edit the records. You could user either multiple subforms, each filtered to the particular memo type, or a single subform and change the type of memo you're editing.
The advantage of this approach is that any corruption of a memo is only going to lose the data for that one memo, rather than causing problems for a whole record of other data. The downside is that it makes the UI somewhat more complicated, but most of that complication can be hidden from the users if you do it right.
C. You can also enhance your ability to recover from problems like this by applying the "Replica Farm" concept:
http://trigeminal.com/usenet/usenet006.asp?1033
There are two ways to implement this, one clearly described in that article, and that is only suggested implicitly.
1. the full replica farm on the server, where you have multiple replicas managed by the synchronizer and a schedule that keeps them all in synch. This maximizes the chance of a successful synch when there's a problem at the hub synchronizer itself.
2. something *not* described in that article, a minimal "replica farm" on the remote computers, with at least one extra replica. One way to implement this is with a backup replica. I do this such that when the user closes the application, it synchs with a backup replica on the same computer. It also does this immediately before any synch with the rest of the replica set when the synch is initiated from the application's synchronization interface. The result of this is that if something goes wrong with the synch with the remote hub and your replica gets messed up somehow, you've still got the backup replica with identical data (because it was synched *before* the failed synch attempt), and you can use it to create a new replica to replace the problem replica if need be.
Well, sorry to be so longwinded, but I felt that since this topic has not been addressed well anywhere else, this was a good place to try to write it up. I hope what I've posted here is helpful.
--
David W. Fenton
David Fenton Associates
http://dfenton.com/DFA/