Hello!
I need help building a query that will count and filter my records.
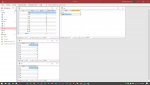
I have a table like this, with several thousend records:

I would like to build a query that will count and filter out all records with same Item and more than one Group and will give result like this:

How should I do that?
I need help building a query that will count and filter my records.
I have a table like this, with several thousend records:
I would like to build a query that will count and filter out all records with same Item and more than one Group and will give result like this:
How should I do that?
")
