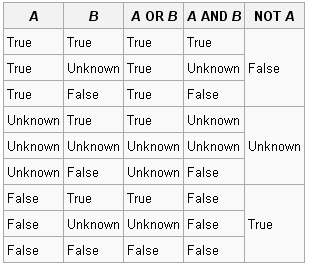
One design problem I've realized is how I want Access to tell me whether there's no given record in a junction table, which the customary answer would be a null.
For a need of concrete example, say I want to track attendance of any given person for a given session. I can then create a junction table consisting of PersonID and SessionID. But do I want to have an extra column indicating whether this person did in fact attended?
If I didn't, I can use nulls to conclude that the person skipped a session. However, if the attendance was changed (let's say that someone has been calling someone else's name during roll and later caught), that means delete query is needed so the attendance check query will now return null for this person, indicating absence. So that means I now have the issue of correcting maintaining the junction table so whenever I look for a null, I know that I won't be looking at stale record that shouldn't been there in first place.
Or I can just add an Yes/No Column of whether a given person did attend a session. Instead of deleting records, it's now a matter of clearing the checkbox if the data changes. There's now no need to delete records, so I can just keep adding records as I like. In this situation, it's actually simpler to add somehow extraneous column than use Null-logic.
Now, I'm sure there are other situations where making a record just to deny something makes no sense, and leaving it as null would be appropriate.
If you read this interesting Wiki article on Nulls, especially the section on criticism thereof, you can see that there has been suggestions to omit nulls entirely from the SQL logic.
So, what are your feelings on this matter? Should Nulls be relied on to be meaningful, and under what circumstances?
For a need of concrete example, say I want to track attendance of any given person for a given session. I can then create a junction table consisting of PersonID and SessionID. But do I want to have an extra column indicating whether this person did in fact attended?
If I didn't, I can use nulls to conclude that the person skipped a session. However, if the attendance was changed (let's say that someone has been calling someone else's name during roll and later caught), that means delete query is needed so the attendance check query will now return null for this person, indicating absence. So that means I now have the issue of correcting maintaining the junction table so whenever I look for a null, I know that I won't be looking at stale record that shouldn't been there in first place.
Or I can just add an Yes/No Column of whether a given person did attend a session. Instead of deleting records, it's now a matter of clearing the checkbox if the data changes. There's now no need to delete records, so I can just keep adding records as I like. In this situation, it's actually simpler to add somehow extraneous column than use Null-logic.
Now, I'm sure there are other situations where making a record just to deny something makes no sense, and leaving it as null would be appropriate.
If you read this interesting Wiki article on Nulls, especially the section on criticism thereof, you can see that there has been suggestions to omit nulls entirely from the SQL logic.
So, what are your feelings on this matter? Should Nulls be relied on to be meaningful, and under what circumstances?
 eek:
eek:  )
)
") Links to employee roles table by the index on the Employee Roles table and links to the question ID by the ID in the questions table. Might be as short as Employee ID, Role ID, Question ID, text of answer. OK, let's add a state code that can mean "Not applicable" or "no data available" or "Employee pleads 5th amendment" or whatever is appropriate.
Links to employee roles table by the index on the Employee Roles table and links to the question ID by the ID in the questions table. Might be as short as Employee ID, Role ID, Question ID, text of answer. OK, let's add a state code that can mean "Not applicable" or "no data available" or "Employee pleads 5th amendment" or whatever is appropriate.