Maximus Primal
Learning and struggling..
- Local time
- Today, 16:06
- Joined
- Aug 15, 2010
- Messages
- 17
I have read a couple of website that explain now to normalize a database structure into the "perfect" model which reduces redunacy and duplication.
They all state that for a database to be right you have to take it to the third level of normlization (3ND?).
Question is, what if you cannot get a database to the third level, say you can only get it to the second level - does that mean your model is flawed and wrong or just that is is not possible to achieve a "perfect" model for it, and does it really matter if you cannot find a way to get it to this third level?
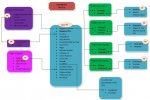
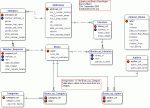
I have my own model for a magazine collection database at the second level currently, and being the first one I have designed I am pleased I got it this far. But I cannot see a way of achieving the requirements of the next level and as yet no one on this board has suggested a possible way or idea on how I can do this - so I am assuming it cannot be done.
So with this mind, if my database is only at the second level am I likely to have any possible issues or would it be safe to go ahead at this point and start the database creation?
I would like some thoughts as I am a non-IT person, in a non-IT job trying to understand concepts and ideas which (at the moment) confuse me and I have no direct personal resources other than the Internet to do this.
Advice and thoughts would be appreicated so I can move forward and not consign this to the "good idea, shame I had no idea how to do it" bin.
Thank you in advance
Max
They all state that for a database to be right you have to take it to the third level of normlization (3ND?).
Question is, what if you cannot get a database to the third level, say you can only get it to the second level - does that mean your model is flawed and wrong or just that is is not possible to achieve a "perfect" model for it, and does it really matter if you cannot find a way to get it to this third level?
I have my own model for a magazine collection database at the second level currently, and being the first one I have designed I am pleased I got it this far. But I cannot see a way of achieving the requirements of the next level and as yet no one on this board has suggested a possible way or idea on how I can do this - so I am assuming it cannot be done.
So with this mind, if my database is only at the second level am I likely to have any possible issues or would it be safe to go ahead at this point and start the database creation?
I would like some thoughts as I am a non-IT person, in a non-IT job trying to understand concepts and ideas which (at the moment) confuse me and I have no direct personal resources other than the Internet to do this.
Advice and thoughts would be appreicated so I can move forward and not consign this to the "good idea, shame I had no idea how to do it" bin.
Thank you in advance
Max
")
