HowardHelp
New member
- Local time
- Today, 05:57
- Joined
- Feb 1, 2021
- Messages
- 26
I must start by saying yes I’m a newbie not experienced unlike die hard access experts.
I joined this forum because it sounded like newbies were welcome, but a minority of experts seem to revel in comments like practice makes perfect etc. and I should know what I'm doing so to them please go and play on Facebook or Twitter if you can’t offer help or maybe you like mocking others with less knowledge the yourselves.
I hope the administrator reads this, sad but there you go.
If you're interested in helping then please read on.
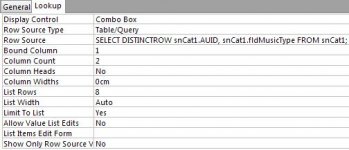
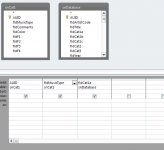
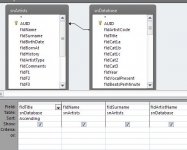
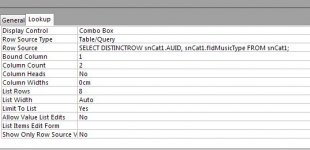
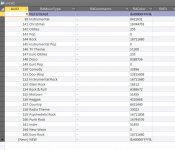
Is it possible to make a simple SQL / code that can convert a known number into text because the way the original database was designed it will show a number instead of text in the form, the list is short so it wouldn’t involve hundreds of variables, maximum 10 an example below.
0 if, replace to = NotEntered
111 if, replace to = Cat
112 if, replace to = Dog
113 if, replace to = Crocodile
The above isn’t the exact names required but I hope you get the idea.
Any help if you want to help would really be appreciated, or a simple NO if it can’t be done.
I joined this forum because it sounded like newbies were welcome, but a minority of experts seem to revel in comments like practice makes perfect etc. and I should know what I'm doing so to them please go and play on Facebook or Twitter if you can’t offer help or maybe you like mocking others with less knowledge the yourselves.
I hope the administrator reads this, sad but there you go.
If you're interested in helping then please read on.
Is it possible to make a simple SQL / code that can convert a known number into text because the way the original database was designed it will show a number instead of text in the form, the list is short so it wouldn’t involve hundreds of variables, maximum 10 an example below.
0 if, replace to = NotEntered
111 if, replace to = Cat
112 if, replace to = Dog
113 if, replace to = Crocodile
The above isn’t the exact names required but I hope you get the idea.
Any help if you want to help would really be appreciated, or a simple NO if it can’t be done.