I was just given the project of creating a database to store and access information that the various engineers involved in design and manufacturing can use to create updated instructions and load information into their modeling software efficiently.
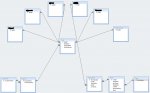
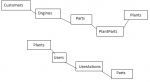
I have *some* experience with database design, but have no actual education in the area of study apart from my personal internet research. I really want to start this project off on the right foot by making sure this database is normalized (and follows all of the important major concepts of a relational database) and organized to match most generic database standards (my primary key is a user-defined text field, is that acceptable?). I have attached a photo of the Database Relationships I've drafted thus far.
I would love any advice from the experienced members here on what I need to do to this database before I can actually start developing the content and functionality of it.
Note: The blacked out table names are processes that every manufactured part goes through. I plan on filling in those tables once the database is normalized.
Any and all help or advice is welcome!
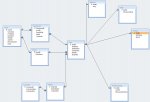
I have *some* experience with database design, but have no actual education in the area of study apart from my personal internet research. I really want to start this project off on the right foot by making sure this database is normalized (and follows all of the important major concepts of a relational database) and organized to match most generic database standards (my primary key is a user-defined text field, is that acceptable?). I have attached a photo of the Database Relationships I've drafted thus far.
I would love any advice from the experienced members here on what I need to do to this database before I can actually start developing the content and functionality of it.
Note: The blacked out table names are processes that every manufactured part goes through. I plan on filling in those tables once the database is normalized.
Any and all help or advice is welcome!