There is a Persian proverb: If you point your finger at others, behold, three fingers point at you.never be able to learn from others
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Solved Key Violation Error Trapping During TransferText Operation
- Thread starter CranstonSnord
- Start date
Nonsense.and you ALWAYS use embedded SQL
You like to talk a lot, and now you seem to be trying to hide your tempered arrogance in many words.
You don't have to dispose of waste that you don't produce. Save yourself all the words and assumptions.
If you want to think again: read the title of the topic.
Efficiency considerations can give a certain feeling, measurements under real conditions provide insights.
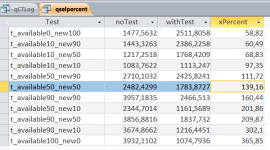
Out of interest, I created a test environment and measured various things.
Initial situation: Destination table with 10,000 values (text) with a unique index, plus text files with different content in 11 variants.
t_available10_new10 means the text file contains 10 percent of entries that are in the destination table and 10 percent of new entries.
These 11 variants are executed once with a simple append query (noTest) and once with a built-in check for duplicates (withTest). Because these are append queries, a new copy of the destination table is used each time.
The entire code run with setting up the test conditions took 3 minutes on my computer. This included 3 runs across the 22 variants. Further details can be found in the attached files.
Under these laboratory conditions with the elimination of other errors the queries can be executed WITHOUT dbFailOnError. If the additional test for duplicates is omitted, this results in runtimes of 58.8 percent when only adding new records to runtimes of 365 percent when only appending existing records. This range can be discussed.
According to the measurements, the tipping point for 100 percent runtime is around 50 percent potential duplicates from the text file.
Important for forming my opinion:
- In practice, you rarely have laboratory conditions where you can exclude the occurrence of other errors such as duplicates.
- In my practice there are rarely precise imports from a text file into exactly one table. It is common for the text file to contain content from reports, and this content is to be divided into several tables from the database schema. When it comes to master tables involved, there will rarely be much that is new, but there will often be a lot that is existing.
In summary, I see myself in at least the same or better position by using the test for duplicates.
Now someone show me my errors in thinking or errors in my measurement environment.
Out of interest, I created a test environment and measured various things.
Initial situation: Destination table with 10,000 values (text) with a unique index, plus text files with different content in 11 variants.
t_available10_new10 means the text file contains 10 percent of entries that are in the destination table and 10 percent of new entries.
These 11 variants are executed once with a simple append query (noTest) and once with a built-in check for duplicates (withTest). Because these are append queries, a new copy of the destination table is used each time.
The entire code run with setting up the test conditions took 3 minutes on my computer. This included 3 runs across the 22 variants. Further details can be found in the attached files.
Under these laboratory conditions with the elimination of other errors the queries can be executed WITHOUT dbFailOnError. If the additional test for duplicates is omitted, this results in runtimes of 58.8 percent when only adding new records to runtimes of 365 percent when only appending existing records. This range can be discussed.
According to the measurements, the tipping point for 100 percent runtime is around 50 percent potential duplicates from the text file.
Important for forming my opinion:
- In practice, you rarely have laboratory conditions where you can exclude the occurrence of other errors such as duplicates.
- In my practice there are rarely precise imports from a text file into exactly one table. It is common for the text file to contain content from reports, and this content is to be divided into several tables from the database schema. When it comes to master tables involved, there will rarely be much that is new, but there will often be a lot that is existing.
In summary, I see myself in at least the same or better position by using the test for duplicates.
Now someone show me my errors in thinking or errors in my measurement environment.
Attachments
- Local time
- Today, 04:04
- Joined
- Feb 28, 2001
- Messages
- 30,910
@ebs17 - The question I have to ask is, what did you do with the duplicates when you detected them? (I don't open someone else's databases on my home machine so I didn't look at your code.)
Looking at this from the outside, I see two people talking past each other. Perhaps I'll just tick you both off, but I hope to do otherwise by adding my two cents' worth.
@Pat Hartman is saying (if I read her correctly) that you have two basic problems here, or two parts to the problem. One of the parts is the heterogenous JOIN; the other is the expected duplicate entries. The difficulty to which she APPEARS to have focused her attention is with the expected duplicates.
I don't want to put words in Pat's mouth but I have to agree with her on what happens IN ACCESS when you make your application code ignore errors. Access, regardless of what you do, will do the import row by agonizing row (RBAR). The DB engine, regardless of what you do, will detect the (expected) duplication where applicable. The next question is whether you trapped the error or didn't trap the error. JET/ACE will disallow the insertion no matter what you do in your error trapping routine because a key violation is still a key violation. So with respect to your test, when a duplicate is detected then a record is rejected, and that is a base-line fact. That is the LEAST you can expect to happen. The question then arises - so what ELSE can you do?
There is an implied code context switch in the innards of the TransferText operation any time it has to respond to an error condition, particularly if it engages the error-trapping dialog box. If you are going to continue after the error AND you are trapping, you have just called a special handling no-parameter subroutine out-of-line with the transfer process. This CANNOT be faster or equal in speed than just letting Access drop the bad record and go one its merry way in the loop, because that drop/proceed is base-line behavior.
Therefore, on simple logic alone, I have to disagree with your statement:
How do you deal with those duplicates after the import is complete? Different question. You can either pre-scan for duplicates (which adds the time of one query equal in size to the import operation) or you can impose some kind of flag during the import operation to show that the record came from the import and then post-scan for non-flagged duplicates. That would add a full-scan query as well. I see a pre-scan or post-scan that doubles the number of records you have to hit OR I see an error handler routine that doesn't always take a straight-through path for its code, and the number of extra trap-based diversions can NEVER make the rest of the loop faster.
Therefore "better position" seems to me to carry some baggage that you have not clarified. What, specifically, makes it better? You aren't going to import more records unless you do something to handle the key duplication. I don't see how that can be faster.
If there is a linguistic situation here, that might account for something - but it doesn't seem so. I just don't see your argument.
Looking at this from the outside, I see two people talking past each other. Perhaps I'll just tick you both off, but I hope to do otherwise by adding my two cents' worth.
@Pat Hartman is saying (if I read her correctly) that you have two basic problems here, or two parts to the problem. One of the parts is the heterogenous JOIN; the other is the expected duplicate entries. The difficulty to which she APPEARS to have focused her attention is with the expected duplicates.
I don't want to put words in Pat's mouth but I have to agree with her on what happens IN ACCESS when you make your application code ignore errors. Access, regardless of what you do, will do the import row by agonizing row (RBAR). The DB engine, regardless of what you do, will detect the (expected) duplication where applicable. The next question is whether you trapped the error or didn't trap the error. JET/ACE will disallow the insertion no matter what you do in your error trapping routine because a key violation is still a key violation. So with respect to your test, when a duplicate is detected then a record is rejected, and that is a base-line fact. That is the LEAST you can expect to happen. The question then arises - so what ELSE can you do?
There is an implied code context switch in the innards of the TransferText operation any time it has to respond to an error condition, particularly if it engages the error-trapping dialog box. If you are going to continue after the error AND you are trapping, you have just called a special handling no-parameter subroutine out-of-line with the transfer process. This CANNOT be faster or equal in speed than just letting Access drop the bad record and go one its merry way in the loop, because that drop/proceed is base-line behavior.
Therefore, on simple logic alone, I have to disagree with your statement:
I see myself in at least the same or better position by using the test for duplicates.
How do you deal with those duplicates after the import is complete? Different question. You can either pre-scan for duplicates (which adds the time of one query equal in size to the import operation) or you can impose some kind of flag during the import operation to show that the record came from the import and then post-scan for non-flagged duplicates. That would add a full-scan query as well. I see a pre-scan or post-scan that doubles the number of records you have to hit OR I see an error handler routine that doesn't always take a straight-through path for its code, and the number of extra trap-based diversions can NEVER make the rest of the loop faster.
Therefore "better position" seems to me to carry some baggage that you have not clarified. What, specifically, makes it better? You aren't going to import more records unless you do something to handle the key duplication. I don't see how that can be faster.
If there is a linguistic situation here, that might account for something - but it doesn't seem so. I just don't see your argument.
Code:
sSQL = "INSERT INTO " & sTable & " (xWord)" & _
" SELECT T.F1 FROM [Text;DSN=MySpec;FMT=Delimited;HDR=no;IMEX=2;CharacterSet=850;" & _
"DATABASE=" & sPath & "].[" & sFile & "] AS T"
Code:
sSQL = "INSERT INTO " & sTable & " (xWord)" & _
" SELECT T.F1 FROM [Text;DSN=MySpec;FMT=Delimited;HDR=no;IMEX=2;CharacterSet=850;" & _
"DATABASE=" & sPath & "].[" & sFile & "] AS T LEFT JOIN " & sTable & " AS D" & _
" ON T.F1 = D.xWord WHERE D.xWord Is Null"Both statements are executed in the test as written with db.Execute sSQL WITHOUT dbFailOnError. The import always takes place against the xWord field, which has a unique index.
In my opinion, the entire import process, which begins with reading the text file and ends with the entries in the table, has been reduced to the core as best as possible. With the connection data to the text file in the query, I save having to link and unlink the text file separately, as described above. Looking at the clock makes mental guesses.
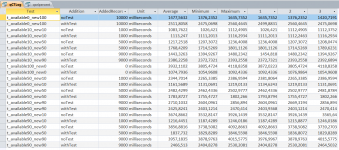
In the first variant, more or fewer duplicates are fired against the index in the table. In the second variant, duplicates are removed using the additional step. The discussions above may lead to the conclusion that the additional testing, whatever it may be, adds a lot of additional effort and is less efficient. I used the required runtime for the entire process as a benchmark because something like this is primarily important for the developer using it as well as for a later user.
What is interesting is that in the process available100-new0, which is all about duplicates, the protection of duplicates purely by the database engine via the unique index performs relatively worst compared to the preliminary check. A 265 percent longer runtime is more than significant.
Now someone can explain to me why this is preferable anyway.
The subject of the study is an everyday and omnipresent task with no particular intellectual challenges. I don't understand why you don't look at numbers, pictures and experimental conditions and become aware of them.Therefore "better position" seems to me to carry some baggage that you have not clarified. What, specifically, makes it better? You aren't going to import more records unless you do something to handle the key duplication. I don't see how that can be faster.
Then at some point the question arises as to whether you CAN'T understand or you don't WANT to understand.
Individual ideas may be correct in themselves. However, if you have to combine specific processes with other processes, then efficiency and ultimately performance result from the interaction of all these processes.
- Local time
- Today, 04:04
- Joined
- Feb 28, 2001
- Messages
- 30,910
There is a linguistic issue based on your post #36. Adding a WHERE xxxx IS NULL clause is, to me, not error trapping. It is a type of filtration. Since filtration is done in-line with other tests, I would agree that you should see minimal difference in speed for the things which pass the filter. To me, filtration as a way to PREVENT errors is perfectly valid. But your choice of calling that "error trapping" confused me because that phrase has a vastly different meaning to me.
I hope that clarifies why I chimed in.
I hope that clarifies why I chimed in.
Yes, if you absolutely have to be right, then it will be so. In my opinion, I have encapsulated the problem extremely accurately. Now you have to remember what the problem was and whether we are all talking about the same problem. My task was to import from a text file into a table without errors and without error messages if duplicates were present.However, it doesn't actually test the problem.
Of course, it's no problem to move the destination tables to your own backend and link them to the frontend - if you can handle tables and backends. Then you can repeat the tests in this sense. However, time measurements should be limited to pure appending processes.
Regarding SQL Server and efficiency, I made the statement that I would prefer not to use Jet-SQL, and with ODBC-linked tables this is used automatically, but rather I would use T-SQL directly with its own import methods. I repeat this because you not only like to ignore errors, but also statements that do not fit into your opinion.
Isn't it time to re-evaluate this statement for yourself and others?never be able to learn from others
Last edited:
Not in my world either. But they also have no reason to do something like that and disrupt the functionality of the application.I my world, users can't just move the BE
However, I don't see any connection to the thread. Errors and error messages as well as their avoidance as well as efficiency and performance considerations are the developer's tasks.
If the user has to help the developer with this, things look bad.
I would really like to see a test environment that encapsulates and shows exactly the problem you describe. Reading from the text file and appending content into the table should be included.
If I am told that my test environment is wrong, I can accept it if there is conclusive evidence or if I am shown an alternative, better environment.
How do I get around the problem? Show me how to handle it with purpose. Follow the claims with actions!
If I am told that my test environment is wrong, I can accept it if there is conclusive evidence or if I am shown an alternative, better environment.
How do I get around the problem? Show me how to handle it with purpose. Follow the claims with actions!
Last edited:
Is this your specific decision, separate from the questioner's topic, or a rearguard action?The table you are updating should be SQL Server
Based on the question you will realize that I will not build an environment for your satisfaction, as you can do that yourself if you are really interested. Self-employment is the better occupation because there is a learning effect.
As a general answer: Of course, the respective destination table can be a table from an external access backend or a table from a SQL server instead of in its own file. If you link this table into the FE, you have the same code.
The only difference is that the destination table is changed in an append query. If I test several variants, and in several runs, I need a separate destination table for each variant and run. The real difference is only in creating tables in the backend and necessarily deleting them, alternatively copying prepared backends and swapping them.
It takes work, but it's not impossible.
Instead of linking external tables to the frontend, you can point your DAO reference or ADODB connection directly to the backend. The queries still remain very much the same.
If I reference SQL Server directly, it makes sense to use T-SQL.

How to import data from .txt file to populate a table in SQL Server
Every day a PPE.txt file with clients data, separated by semicolon and always with the same layout is stored to a specific file directory. Every day someone has to update a specific table from our
 stackoverflow.com
stackoverflow.com
I don't know what numbers will result from measurements under these conditions. You are welcome to present and discuss these numbers here.
Since you talked about statistics above: The variants can also be expanded so that, for example, 5 duplicates are fired on 500,000 records in the destination table. Everything conceivable is possible. You then only need more time for test creation and test execution. Anyone with a high level of interest and a high desire to persuade will be happy to spend their time on it.
I reject the accusation that I would circumvent the problem.
The question of whether you can trust a text file coming from outside to the extent that it contains no errors other than possible duplicates and whether you can therefore ignore errors or whether it is better to ward off errors continues to arise. As I have written several times, I only have one clear answer.
I never talked about anything other than text file as a data source.the input data some type of text file - .txt, .cvs, .xls, .xlsx.
An Excel table can be integrated into the SQL statement in a similar way, but there is no import specification, which increases the risk of errors during import (columns in Excel tables are not data type-safe). This is not a plus point for ignoring errors.
Excel connection strings - ConnectionStrings.com
Connection strings for Excel. Connect using CData ADO.NET Provider for Excel, Microsoft.ACE.OLEDB.12.0, Microsoft.Jet.OLEDB.4.0, OleDbConnection.
www.connectionstrings.com
Last edited:
@Pat Hartman
I don't know if it calms you down.
Of course, I know and recognize that a text file and therefore the text table read cannot have an index.
Due to the use of LEFT JOIN, only a comparison can be made between rows and rows, the exact key of the row against the key of the row, which is more inefficient than using the index in the test. And foregoing an explicit test creates the expectation that additional time will be saved. So far I can understand and accept everything.
But the import does not just consist of checking and preventing duplicates. In any case, reading the source data and writing data to the destination table is also included. Runtime efficiency is reflected in performance. So I can only use runtimes of the minimal necessary process to make a truly practical assessment.
A chain is as strong as the weakest link. It's no use if there is a particularly strong link in the chain.
In case @isladogs reads along here:
You are recognized as an external person for speed comparison tests in the forum. If you want, you are welcome to use the entire content of the thread for your own test, even as part of your own series.
The topic of unwanted duplicates, errors and error messages should be a topic of general interest and deserve some attention.
I don't know if it calms you down.
Of course, I know and recognize that a text file and therefore the text table read cannot have an index.
Due to the use of LEFT JOIN, only a comparison can be made between rows and rows, the exact key of the row against the key of the row, which is more inefficient than using the index in the test. And foregoing an explicit test creates the expectation that additional time will be saved. So far I can understand and accept everything.
But the import does not just consist of checking and preventing duplicates. In any case, reading the source data and writing data to the destination table is also included. Runtime efficiency is reflected in performance. So I can only use runtimes of the minimal necessary process to make a truly practical assessment.
A chain is as strong as the weakest link. It's no use if there is a particularly strong link in the chain.
In case @isladogs reads along here:
You are recognized as an external person for speed comparison tests in the forum. If you want, you are welcome to use the entire content of the thread for your own test, even as part of your own series.
The topic of unwanted duplicates, errors and error messages should be a topic of general interest and deserve some attention.
Last edited:
What is the actual impact of the problem that I do not understand?You still do not understand the problem.
Does the query not work or is incorrect?
Does it extend run times, in addition to what I measured?
Does it destroy the database?
Does it annoy the network operator?
Without negative effects, it doesn't really matter. I don't really need to know how to make the very best snow igloos unless I go anywhere near the Arctic.
Sure, Access, i.e. Jet-SQL, works locally and has to load the required data from the backends into its own area. This is always the case and not specific to this case. Since there are no usable indexes for filtering, it's really about entire tables that have to be loaded. However, only the key fields are loaded in the first step, not the entire records. In addition, Jet-SQL must communicate with T-SQL; it cannot directly affect the DB machine of the SQL Server.
So where is the real problem? There would be a real problem if the running times were to become unacceptably longer due to all the stories that had to be completed. In my test this wasn't the case. However, record numbers from statistics that are common to me were used.
But what you didn't register, at least not noticeable in the feedback: If I send a query in T-SQL to the SQL server via ADO, Jet-SQL and therefore downloading data into local Access is no longer an issue. I am convinced that you know that. But then this knowledge should also appear in the discussion.
So where is the real problem? There would be a real problem if the running times were to become unacceptably longer due to all the stories that had to be completed. In my test this wasn't the case. However, record numbers from statistics that are common to me were used.
But what you didn't register, at least not noticeable in the feedback: If I send a query in T-SQL to the SQL server via ADO, Jet-SQL and therefore downloading data into local Access is no longer an issue. I am convinced that you know that. But then this knowledge should also appear in the discussion.
isladogs
Access MVP / VIP
- Local time
- Today, 09:04
- Joined
- Jan 14, 2017
- Messages
- 19,543
Despite being name checked more than once in this lengthy thread by both @ebs17 and @Pat Hartman, I have deliberately kept clear of this 'discussion'.
It seems to me that you are both dogmatically restating the same views endlessly and are both determined to have the last word.
That is something I've certainly been guilty of at various times!
The last thing this thread needs is a third equally stubborn individual (me!) to complicate matters even further.
We're now on post #53 and the OP hasn't been seen since post #14. Is continuing this excessively long thread really serving any purpose?
It seems to me that you are both dogmatically restating the same views endlessly and are both determined to have the last word.
That is something I've certainly been guilty of at various times!
The last thing this thread needs is a third equally stubborn individual (me!) to complicate matters even further.
We're now on post #53 and the OP hasn't been seen since post #14. Is continuing this excessively long thread really serving any purpose?
If no third party is interested in the content, then no longer. Thanks for your report.Is continuing this excessively long thread really serving any purpose?
Another opinion would perhaps help me to clarify where my mistakes may lie or to clarify to me THE PROBLEM (which somehow shifts when I try to approach it). But I won't die from an indecisive or lost discussion. Also: A problem that I don't have doesn't bother me.
Last edited:
For the hundredth time: What bothers you about the "inefficiency of heterogeneous joins" when runtimes across the entire import are comparable to those with avoidance or sometimes even better?
If you want to hear that they in themselves represent an efficiency problem: Sure. I always prefer using indexes for queries; this attitude of mine should be clear from some of my contributions. But JOINs with tables from the same database without using indexes have practically the same problem. Therefore, highlighting a query with a text file is way over the top, when it comes to practice and not ideology
If you want to hear that they in themselves represent an efficiency problem: Sure. I always prefer using indexes for queries; this attitude of mine should be clear from some of my contributions. But JOINs with tables from the same database without using indexes have practically the same problem. Therefore, highlighting a query with a text file is way over the top, when it comes to practice and not ideology
Last edited:
After all, it addresses exactly the question asked by @CranstonSnord, and that is the most important thing in the topic.Your sample does not replicate the problem.
If you have your own problem, open your own thread and wait for replies.
I would shyly ask if someone else understood you. The only one who spoke up runs away in horror.
Last edited:
Similar threads
- Replies
- 22
- Views
- 1,398
- Replies
- 18
- Views
- 643
- Replies
- 12
- Views
- 1,778
- Replies
- 11
- Views
- 948
- Replies
- 10
- Views
- 1,834
Users who are viewing this thread
Total: 1 (members: 0, guests: 1)