shamal
Registered User.
- Local time
- Today, 06:27
- Joined
- Sep 28, 2013
- Messages
- 84
Welcome..
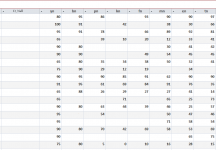
How to calculate empty fields using the Visual Basic function.
I used this function in a query, but I want it in a function using Visual Basic
D_Null: IIf(IsNull([sn]);1;0)+IIf(IsNull([an]);1;0)+IIf(IsNull([en]);1;0)+IIf(IsNull([tn]);1;0)+IIf(IsNull([mn]);1;0)+IIf(IsNull([kn]);1;0)
How to calculate empty fields using the Visual Basic function.
I used this function in a query, but I want it in a function using Visual Basic
D_Null: IIf(IsNull([sn]);1;0)+IIf(IsNull([an]);1;0)+IIf(IsNull([en]);1;0)+IIf(IsNull([tn]);1;0)+IIf(IsNull([mn]);1;0)+IIf(IsNull([kn]);1;0)