isladogs
Access MVP / VIP
- Local time
- Today, 17:57
- Joined
- Jan 14, 2017
- Messages
- 19,550
Re: Post #22
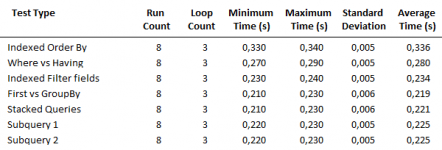
The example you have given is a very common use for a subquery (Top N per group).
I would ALWAYS use a subquery for this task. I haven't spent a lot of time thinking about it, but I cannot think of a way that this could be done in a single query that doesn't use a subquery
If you are going to give examples, please supply both the subquery variant & a standard single query alternative together with data so it can be tested by others.
In the meantime, I've been working on another speed test that was first suggested by another AWF member CJ_London at the Access Europe presentation I did back in Sept. He suggested I compared the speeds of various aggregate queries including the use of non equi-joins and subqueries.
I devised a task to compare 5 different types of aggregate query using 2 tables
There were two inequalities and a Count.
The 5 variants were
a) JOINS with non-equal WHERE criteria
b) Non equi joins
c) As a) but Cartesian (no JOINS)
d) As a) but Stacked
e) As above but with the main table and a subquery for the second table
The 2 tables had about 1500 & 4700 records respectively. The query output had 97 records
These were the results

As you can see the first 4 were all very similar with the subquery being about 14% slower.
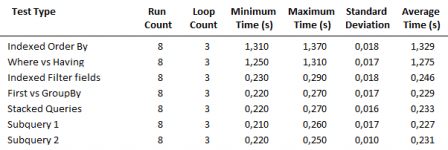
Out of interest, I repeated the tests but this time I added an index to the field used in the Count.
The first four were all about 4% slower but note the massive effect on the subquery

I'm still waiting to see a subquery perform faster than any equivalent single query (discounting my own 0.001s improvement in the last post!)
The example you have given is a very common use for a subquery (Top N per group).
I would ALWAYS use a subquery for this task. I haven't spent a lot of time thinking about it, but I cannot think of a way that this could be done in a single query that doesn't use a subquery
If you are going to give examples, please supply both the subquery variant & a standard single query alternative together with data so it can be tested by others.
In the meantime, I've been working on another speed test that was first suggested by another AWF member CJ_London at the Access Europe presentation I did back in Sept. He suggested I compared the speeds of various aggregate queries including the use of non equi-joins and subqueries.
I devised a task to compare 5 different types of aggregate query using 2 tables
There were two inequalities and a Count.
The 5 variants were
a) JOINS with non-equal WHERE criteria
b) Non equi joins
c) As a) but Cartesian (no JOINS)
d) As a) but Stacked
e) As above but with the main table and a subquery for the second table
The 2 tables had about 1500 & 4700 records respectively. The query output had 97 records
These were the results
As you can see the first 4 were all very similar with the subquery being about 14% slower.
Out of interest, I repeated the tests but this time I added an index to the field used in the Count.
The first four were all about 4% slower but note the massive effect on the subquery
I'm still waiting to see a subquery perform faster than any equivalent single query (discounting my own 0.001s improvement in the last post!)


") just getting over man flu
just getting over man flu
