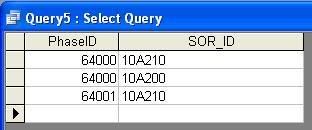
I am trying to enforce referential integrity on tables where a compound key is implemented.
I want to enforce integrity on the DETAIL table so that it can only use an SOR_ID from the SOR table that has a corresponding PhaseID in the HEADER table. Here is my current diagram:
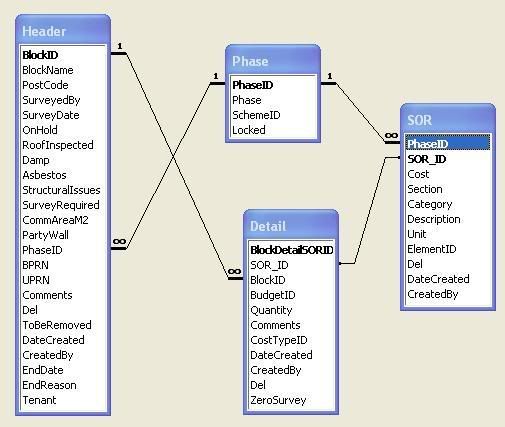
The only solution i can think of at the moment is to build two queries. One which concatenates SOR.PhaseID & SOR.SOR_ID, and another which concatenates HEADER.PhaseID & DETAIL.SOR_ID... and then create a relationship between the two queries.
There must be a much nicer way of doing this though?
I want to enforce integrity on the DETAIL table so that it can only use an SOR_ID from the SOR table that has a corresponding PhaseID in the HEADER table. Here is my current diagram:
The only solution i can think of at the moment is to build two queries. One which concatenates SOR.PhaseID & SOR.SOR_ID, and another which concatenates HEADER.PhaseID & DETAIL.SOR_ID... and then create a relationship between the two queries.
There must be a much nicer way of doing this though?