You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Comparing two tables to see if there is any match
- Thread starter aman
- Start date
Jdraw, the lengths of the strings vary in both the tables. I can't change that as we got these two tables from the clients. The only thing is I need to match each policynumber of Tblcancellationmodes with all the policynumbers of AnnutiesTBL. As length varies so we need to use LIKE operator to check if each policynumber of Tblcancellationmodes is present in any part of the policynumber of ANnutiesTBL.
Unfortunately, I can't upload the access database so I have sent you the notepad file. Please check it again. As thus is how we need to match policy numbers of both tables..
Then I need to store ID,policynumber from Tblcancellationmodes and ID from AnnutiesTBL in a new table.
I hope it made everything clear this time..thanks
Unfortunately, I can't upload the access database so I have sent you the notepad file. Please check it again. As thus is how we need to match policy numbers of both tables..
Then I need to store ID,policynumber from Tblcancellationmodes and ID from AnnutiesTBL in a new table.
I hope it made everything clear this time..thanks
- Local time
- Today, 09:05
- Joined
- Jan 23, 2006
- Messages
- 15,483
I copied your sample data, moved it to 2 text files. Adjusted PolicyNumber to APolicyNumber and CPolicyNumber in respective tables. Imported the data into Access using the APolicyNumber and CPolicyNumber as text.
Tables were created successfully.
Created SQL
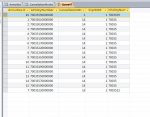
And got the result in attached jpg.
NOTE: Because the PolicyNumbers are of varying lengths, I used the Instr function to find string within string.
I hope this is helpful.
Tables were created successfully.
Created SQL
Code:
SELECT Annuities.ID
,Annuities.APolicyNumber
,CancellationModes.ID
,InStr([Annuities].[APolicyNumber], [CancellationModes].[CPolicyNumber])
,CancellationModes.CPolicyNumber
FROM Annuities
,CancellationModes
WHERE (((InStr([Annuities].[APolicyNumber], [CancellationModes].[CPolicyNumber])) > 0));And got the result in attached jpg.
NOTE: Because the PolicyNumbers are of varying lengths, I used the Instr function to find string within string.
I hope this is helpful.
Attachments
Thanks for this Jdraw. Sorry to be a pain but now there is little change in the requirement. Now I need to match each policynumber of TBLCancellationModes with policynumbers in Annuties but just in the beginning of the string. As now we use Instr function to see if the policynumber is present in any part of AnnutiesTBL policynumber. But now we need to check if Policynumner is present in the beginning of the Annuties POlicynumber string...
that means something like: TBLCancellationModes.PolicyNumber Like AnnutiesTBL.PolicyNumber *
and not in any part of the substring. Like in the attached notepad only two policy numbers match i.e 7003531, 7003541
Please see attached.
that means something like: TBLCancellationModes.PolicyNumber Like AnnutiesTBL.PolicyNumber *
and not in any part of the substring. Like in the attached notepad only two policy numbers match i.e 7003531, 7003541
Please see attached.
VBAnet, Its actually the other way around. The AnnutiesTBL contains extra digits after each Policy number. The TBLCancellationModes contains right Policy Numbers. So basically we need to match each policy number of TBLCancellationModes with all the policy numbers of AnnutiesTBL to see if there is any match.. if the match occurs then store TBLCancellationModes.ID,TBLCancellationModes.PolicyNumber,AnnutiesTBLID into a Table named "KLMAnnutiesTBL".
Thanks
Thanks
VBAnet, If I write the below query then keeps on running .It is talking ages and nothing is coming up.
Code:
SELECT TBLCancellationModes.*, AnnutiesTBL.ID
FROM TBLCancellationModes INNER JOIN AnnutiesTBL ON AnnutiesTBL.PolicyNumber like TBLCancellationModes.PolicyNumber & "*";- Local time
- Today, 09:05
- Joined
- Jan 23, 2006
- Messages
- 15,483
...now there is little change in the requirement. Now I need to match each policynumber of TBLCancellationModes
with policynumbers in Annuties but just in the beginning of the string.
If the string has to be at the beginning, then you could still use InStr but change the position criteria to =1
Code:
SELECT Annuities.ID
,Annuities.APolicyNumber
,CancellationModes.ID
,InStr([Annuities].[APolicyNumber], [CancellationModes].[CPolicyNumber])
,CancellationModes.CPolicyNumber
FROM Annuities
,CancellationModes
WHERE (((InStr([Annuities].[APolicyNumber], [CancellationModes].[CPolicyNumber]))[COLOR="Red"] = 1[/COLOR]))How big are both tables? And are those fields indexed?
VbANet, TBLCancellationModes contain 344,955 records and AnnutiesTBL stores 109,213 records. Yes the policy numbers in both tables are indexed.
- Local time
- Today, 09:05
- Joined
- Jan 23, 2006
- Messages
- 15,483
@aman,
With respect, you have tables that have a basic design issue in my view. The PolicyNumbers, if they are meant for identification and comparability, should have the same datatype and format. Since your PolicyNumbers can be of different lengths and seem to contain extraneous trailing 0s, they can not be tested for equality. You are trying to match patterns/substrings.
I can not tell you how long it will take to run the query against all of your real data. I can tell you that if this is a recurring process, then you should take steps to redesign to take advantage of the build in capabilities of the database system itself --consistent data formats.
Another observation is that your requirements seem to be changing and that is not a good sign for a production operation. Can you tell readers more about this process you are trying to automate/resolve? Is it recurring? Policies and Cancellations would tend to suggest insurance, people and finance. The current query attempts seem a little "amateurish" to be dealing with this.
However, if this is all a learning exercise, then you are experiencing some of the issues associated with database table and field design. I don't think that the LIKE operator can take advantage of indexing, so use of LIKE is not likely to lessen your query execution time.
As always, a clear description of your environment, your business and the current issue in business terms would be very helpful. Too often questions are posed in Access jargon with little background and without an analysis of options. I'm not suggesting you have done anything wrong, I'm trying to highlight that readers (and me specifically) are trying to respond with some focus to a problem we don't really understand.
I hope this is useful, and do hope you resolve the issues.
With respect, you have tables that have a basic design issue in my view. The PolicyNumbers, if they are meant for identification and comparability, should have the same datatype and format. Since your PolicyNumbers can be of different lengths and seem to contain extraneous trailing 0s, they can not be tested for equality. You are trying to match patterns/substrings.
I can not tell you how long it will take to run the query against all of your real data. I can tell you that if this is a recurring process, then you should take steps to redesign to take advantage of the build in capabilities of the database system itself --consistent data formats.
Another observation is that your requirements seem to be changing and that is not a good sign for a production operation. Can you tell readers more about this process you are trying to automate/resolve? Is it recurring? Policies and Cancellations would tend to suggest insurance, people and finance. The current query attempts seem a little "amateurish" to be dealing with this.
However, if this is all a learning exercise, then you are experiencing some of the issues associated with database table and field design. I don't think that the LIKE operator can take advantage of indexing, so use of LIKE is not likely to lessen your query execution time.
As always, a clear description of your environment, your business and the current issue in business terms would be very helpful. Too often questions are posed in Access jargon with little background and without an analysis of options. I'm not suggesting you have done anything wrong, I'm trying to highlight that readers (and me specifically) are trying to respond with some focus to a problem we don't really understand.
I hope this is useful, and do hope you resolve the issues.
Good point jd. I think it depends on usage. If none of the wildchard characters are used then it may use indexing (which defeats the whole point of doing a pattern match). But the point of using LIKE in this case was to take advantage of the INNER JOIN which, naturally, performs better than a WHERE clause.However, if this is all a learning exercise, then you are experiencing some of the issues associated with database table and field design. I don't think that the LIKE operator can take advantage of indexing, so use of LIKE is not likely to lessen your query execution time.
We can re-write it to look like this:
Code:
SELECT TBLCancellationModes.*, AnnutiesTBL.ID
FROM TBLCancellationModes INNER JOIN AnnutiesTBL ON TBLCancellationModes.PolicyNumber = Left(AnnutiesTBL.PolicyNumber, Len(TBLCancellationModes.PolicyNumber));Regardless of all that, jdraw has highlighted your main problem, so work with him on that.
Jdraw I understand what you mean. Just to make sure its not recurring process. I just got these two tables and have to match them. I haven't created the tables. Yes I work in Finance/Insurance company. This is not going to happen again. I have given these two table to match the policy numbers. I just have to do it once and let them know as its very difficult to match the policy numbers for them(Layman).
Thanks
Thanks
Similar threads
- Replies
- 5
- Views
- 491
- Replies
- 23
- Views
- 1,296
- Replies
- 5
- Views
- 657
- Replies
- 11
- Views
- 948
Users who are viewing this thread
Total: 1 (members: 0, guests: 1)