Prepare yourself....
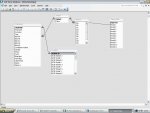
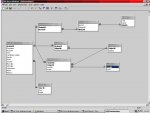
Nearly all of your tables contain repeating groups which goes against database design.
A database should grown downwards and not stretch wider and wider. So, if you have something that goes Field1, Field2, Field3, Field...n then that is a good indication that it deserves a table of its own
A table should contain information pertaining to one thing. Everything in the table should be dependant upon the primary key.
An school example, as you have posted, would have student details:
i.e.
StudentID (autonumber)
StudentForename (text)
StudentSurname (text)
Tutor (text)
English (Yes/No)
French (Yes/No)
German (Yes/No)
Maths (Yes/No)
....
and so on, and so forth...
Now, looking at those fields we have identified that our "object" is a student and therefore everything in this table must be dependant upon the student. The StudentID will be our primary key. So, obviously the students' names will be dependant on the StudentID but the Tutor isn't. The tutor does not depend on that particular student but can apply to many other students and therefore becomes another "object" to factor into your database.
So we make a a table for Tutors:
TutorID (autonumber)
TutorForename (text)
TutorSurname (text)
This stores all our tutors. But, going back the student table we still want to identify who our students' tutors are. So, we create a
foreign key.
StudentID (autonumber)
StudentForename (text)
StudentSurname (text)
TutorID (number)
English (Yes/No)
French (Yes/No)
German (Yes/No)
Maths (Yes/No)
....
and so on, and so forth...
Note now that the Tutor field has been removed and replaced with the numerical field TutorID. This stores the autonumber value relating to a tutor held in the tutors table. The relationship created would be a one-to-many as one tutor can have many students. (I'll discuss many-to-many i.e. many students can have many tutors and
vice versa later.)
The reason why this is better, for one, is to imagine a female teacher called Mrs Sexy. She has a number of students and then one day she gets married and becomes Mrs Frump. In the first case (Tutor field) you would be required to manually update every record in the Tutor field to ensure all trace of Mrs Sexy has gone. With the second example, all that's needed is to change the surname in the Tutors table and, because the ID key is used in the other table,
all the records in the student table are immediately updated.
Now, to the next problem. The tutors are sorted out but there is a repeating group: English, French, German, Maths.
The first thing this says is: subjects are deserving of a table of their own. In other words: Subjects are an object within our database design.
So, we create a new table:
SubjectID (autonumber)
Subject (text)
But we can't do the same thing this time as out students can have many subjects and our subjects can be taken by many students. Now we have a many-to-many relationship. Access doesn't immediately support this type of join so we have to simulate it with
another table. A junction table, if you will.
This table will have the fields:
StudentID (number)
SubjectID (number)
It contains foreign keys to the student table and the subject table respectvely. These two fields (even though they are foreign keys) can also be selected to be the primary key of this table. And they should. This will ensure that over the two fields there are no duplicates meaning that John Smith can only do English once.
So, we relate these foreign keys to their respective tables. Thus we have two one-to-many joins that simulate a many-to-many relationship.
So, we have four tables from the initial one. We can declare our database "normalised". Having your database normalised reduces the risk of problems in design and future maintenance. Afterall, you don't want to have to come back and add a new subject in to a denormalised table when the school decides to offer a course in Latin, do you?
That would mean having to rebuld queries, forms, reports, and maybe even touching up code. Having it all normalised means you'd just add Latin into the Subjects table and that's it!
A database will work for most people if it is normalised to Third Normal Form.
The forms are:
- 1st Normal Form (1NF): The purpose of this is to ensure that repeating groups (or duplicate columns) are removed from the same table and that each row of data is identified by a unique column (primary key);
- 2nd Normal Form (2NF): This Normal Form is used to eliminate functional dependencies on partial key fields from your table (think of the TutorID example above) and placing these functional dependencies in a new table;
- 3rd Normal Form: (3NF): The idea of this is to eliminate functional dependencies on non-key fields (storing calculated values) which basically means we eliminate any calculable values. If we have the quantity and the price then we don't need to store the total cost as it is calculable anytime. And if we did store the total cost the margin for error increases as we could easily change the price field but the total cost wouldn't change without intervention.
If a database is in 2nd Normal Form then it
is in 1st Normal Form. If a database is in 3rd Normal Form then it
is in 2nd and 1st Normal Form.
So, now to your problem:

You can probably see now that your database is in complete violation of 1st Normal Form.

I don't fully know what the fields in your tables signify but the only table that looks semi-okay is the students table although details such as Block1, Block 2 (think 1NF) will cause problems.
It would seem that you have a few many-to-many relationships to simulate.
A tutors table will be necessary.
A subjects table definitely.
I'll let you think about it more now that you should have a better understanding and then you can post back with more questions.
Good luck.