- Local time
- Today, 09:33
- Joined
- Sep 12, 2006
- Messages
- 16,030
I have an excel file with addresses including new lines that are respected in the original excel file.
If I import the file to a new table in Access (I am using A2003), the address stores this, with chr(13) chr(10) as line feeds.
2 Banana Road
Village
Leicester
Leicestershire
LE4 1BA
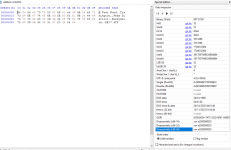
but it displays in the Access table, and on an Access query and form as the image below with no line breaks.
I've copied and pasted the text into notepad, and the line breaks display, and show correctly as #0D and #0A in a hex editor.
Thinking about it, I have had a similar behaviour in a different database using A2016. In both cases the details show correctly on screen, but when exported to excel or a csv, the CRLF characters just disappear, and do not get respected.
What am I missing?
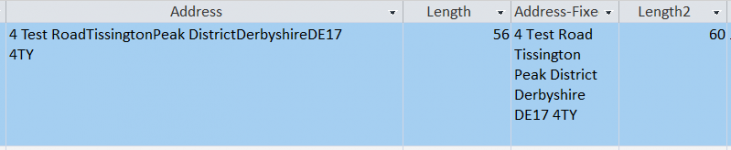
Edit. Actually there is something curious, because access is reporting the length of the string in the query as 54 character, and there are 6 spaces to the right of the end of the postcode. The aren't real spaces, as trim doesn't remove them. See the second screen shot.
Notepad actually reports the string as 56 characters, being 48 characters as above plus 4 CRLF line ends.
If I import the file to a new table in Access (I am using A2003), the address stores this, with chr(13) chr(10) as line feeds.
2 Banana Road
Village
Leicester
Leicestershire
LE4 1BA
but it displays in the Access table, and on an Access query and form as the image below with no line breaks.
I've copied and pasted the text into notepad, and the line breaks display, and show correctly as #0D and #0A in a hex editor.
Thinking about it, I have had a similar behaviour in a different database using A2016. In both cases the details show correctly on screen, but when exported to excel or a csv, the CRLF characters just disappear, and do not get respected.
What am I missing?
Edit. Actually there is something curious, because access is reporting the length of the string in the query as 54 character, and there are 6 spaces to the right of the end of the postcode. The aren't real spaces, as trim doesn't remove them. See the second screen shot.
Notepad actually reports the string as 56 characters, being 48 characters as above plus 4 CRLF line ends.
Attachments


Last edited: