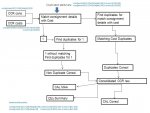
hi people, i have a problem here which i hope you can enlighten me abt.
my database has duplicates due to different currencies used. The currency value is not duplicated but the weight is. sorry if i am confusing you so its better that i give an example.
consignment ID [12345] Weight [100] Currency [USD] Cost [300]
consignment ID [12345] Weight [100] Currency [AUD] Cost [800]
An item with consignment ID [12345] is paid in 2 currencies (USD and AUD). The different currency causes record to be duplicated. the Weight is duplicate but not cost. So, I need to remove one of the weight so it reflects the actual weight which is [100] and i need to add together USD300 + AUD800 and convert to EURO.
i am ok with the currency conversion and i divide the weight by 2 in the query so i can get the actual weight which is 100. Below is what i have from the query
consignment ID [12345] Weight [50] Currency [USD] Cost [300]
consignment ID [12345] Weight [50] Currency [AUD] Cost [800]
it seems as though 50(KG) is charged in USD while 50(KG) is charged in AUD which is not the case.
Can someone advise me how to adjust my query so i get the following:
consignment ID [12345] Weight [100] Currency [USD] Cost [300]
consignment ID [12345] Weight [0] Currency [AUD] Cost [800]
so user know the 2nd record is duplicated (since they know it is impossible to have an item weighing 0 and cost something).
that means i need to "Zerorise" the "weight" field of 2nd record without affecting the weight value of the 1st record.
Pls advise. Thanks!!!
my database has duplicates due to different currencies used. The currency value is not duplicated but the weight is. sorry if i am confusing you so its better that i give an example.
consignment ID [12345] Weight [100] Currency [USD] Cost [300]
consignment ID [12345] Weight [100] Currency [AUD] Cost [800]
An item with consignment ID [12345] is paid in 2 currencies (USD and AUD). The different currency causes record to be duplicated. the Weight is duplicate but not cost. So, I need to remove one of the weight so it reflects the actual weight which is [100] and i need to add together USD300 + AUD800 and convert to EURO.
i am ok with the currency conversion and i divide the weight by 2 in the query so i can get the actual weight which is 100. Below is what i have from the query
consignment ID [12345] Weight [50] Currency [USD] Cost [300]
consignment ID [12345] Weight [50] Currency [AUD] Cost [800]
it seems as though 50(KG) is charged in USD while 50(KG) is charged in AUD which is not the case.
Can someone advise me how to adjust my query so i get the following:
consignment ID [12345] Weight [100] Currency [USD] Cost [300]
consignment ID [12345] Weight [0] Currency [AUD] Cost [800]
so user know the 2nd record is duplicated (since they know it is impossible to have an item weighing 0 and cost something).
that means i need to "Zerorise" the "weight" field of 2nd record without affecting the weight value of the 1st record.
Pls advise. Thanks!!!