First of all: I appreciate your statements and your work shown, such as the speed tests. I don't want to offend anyone personally. I don't typecast anyone. At best, only visible statements and visible actions can flow into my personal and insignificant evaluation. Repeated core sentences are undoubtedly very visible, I don't know the life work of people at all in case of doubt.
My core statement on several topics was and is: General statements about designs, here called subqueries, which can be very different in formulation and place of occurrence, are technically very debatable.
The slowness of the 0.15 seconds would be associated more with the speed of the 0.11 seconds than with the slowness of the 84 seconds. If @Brother Arnold (like many others observed) had not thought of NOT IN as the first (and only?) possible solution, but NOT EXISTS, the performance would most likely have been satisfactory and would not have given reason to ask in the forum. The query could also be interpreted as "what's wrong", and the bigger mistake is the lack of index usage, not the use of a subquery per se. So I made this addition to the topic.
Of course, if I realize that there can be more than one solution to a query and if I can also formulate such variants, then it makes sense to compare and choose the best one. But I have to skip this double "if" for now.
The fastest option is a good candidate for selection. Adequate speed might be sufficient though. Personally, I have other aspects that are relevant to my assessment.
Filter: The task set at the beginning is filtering. Filtering requirements can be more extensive and complex, for example as a combination of several conditions in either OR or AND logic. A JOIN has filtering properties. Implementing multiple and variable conditions using JOINs should be more strenuous compared to being able to limit yourself to the WHERE part of a query. Can one imagine a FormFilter that is preferably implemented via JOINs?
More extensive tasks: In (my) practice, you also have to deal with data models, where you don't just have to consider one or two tables, but sometimes 5, 6, ... 8 tables, of which there may also be several instances of the same table. Additional JOIN operations can become an adventure. Subqueries help me to read and understand a complete query process from table data to the end result, because I have the complete processing in one view and in a context and can quickly recognize, for example, superfluous intermediate sorting and superfluous table fields that are carried along. Understanding also helps in developing and later maintaining the instruction.
Ensuring that a query can be updated is by no means a rare wish or requirement.
I often have to deal with non-simple queries. The longest statement in Jet was probably more than 1200 characters long (using short table aliases). A lot happens, but it doesn't have to result in a performance or stability problem.
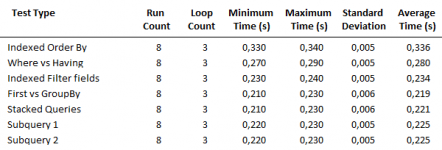
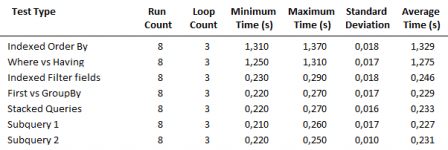
In my own cursory testing, I find the following statement to be competitive:
The practical case that the PupilData table not only contains the birth cohorts 2004 and 2005, but all of them, should be interesting, so the selection will be much more selective.
I not only looked at the results, but also at the test environment.
The total times of 6 query executions - (OpenQuery + DCount) * 3 - are output as results to the surface. The viewer should be made aware of this or be solved differently.
In practice, it is unlikely that an identical query will be executed several times immediately. "Significant" differences in the absolute amount for each individual query are then presented somewhat differently.
In my own test, I would run different queries individually and alternately to reduce the influence of cache, and then repeat the entire run several times. Single query:
The overhead from the recordset object is not very large. For exact measurements you would have to determine it (I don't know how) and subtract it.
With a flagship database, I would also pay attention to the little things. The reader will surely want to copy correctly.
Index planning
PRCodes
Duplicate index on Code
PupilData
A composite index using Surname and Forename makes sense because of the sorting in the query. Index on Forename is not used in the given constellation.
PRecords
Duplicate index on PastoralRecordID. Single indexes on Code and PupilID duplicate because RI (foreign keys are automatically indexed when referential integrity is set to a relationship, but this is not easily visible). Composite index using PupilID and Code makes sense because of grouping in query.
Duplicate indexes bring no benefit. However, they still have to be managed and therefore have a braking effect on writing actions.
The composite indexes mentioned can have a direct effect on performance if the SQL optimizer cooperates. In a description of performance, one should not neglect this, as well as index use in general.
Such a grouping across a huge list of fields occurs in 9 out of 11 queries. In my opinion, this is a catastrophe in itself and should not happen without great need. Certainly it should be discussed separately. Grouping is a comparative operation and thus grateful for index usage. Index usage for such a monster of field listing is unthinkable, not for calculated fields anyway. How do you get to that, aside from slipping your finger on the function key in the QBE?
A JOIN has a filtering function, but also a multiplying function. When several tables are joined, the contents of individual tables in the query are duplicated, and this is usually the first step in processing the query. In the query result, however, you no longer want to see duplicates, there is a "necessity" to group them (as far as possible).
The bottom line is that one can ask oneself how efficient it will be to first multiply content and thus also increase the number of data records in order to then reduce them again ... if you could leave content unique throughout.
I also look forward to feedback.
My core statement on several topics was and is: General statements about designs, here called subqueries, which can be very different in formulation and place of occurrence, are technically very debatable.
#12: 84.67188s / 0.1523438s / 0.1171875sA blanket disqualification is not convincing
The slowness of the 0.15 seconds would be associated more with the speed of the 0.11 seconds than with the slowness of the 84 seconds. If @Brother Arnold (like many others observed) had not thought of NOT IN as the first (and only?) possible solution, but NOT EXISTS, the performance would most likely have been satisfactory and would not have given reason to ask in the forum. The query could also be interpreted as "what's wrong", and the bigger mistake is the lack of index usage, not the use of a subquery per se. So I made this addition to the topic.
Of course, if I realize that there can be more than one solution to a query and if I can also formulate such variants, then it makes sense to compare and choose the best one. But I have to skip this double "if" for now.
The fastest option is a good candidate for selection. Adequate speed might be sufficient though. Personally, I have other aspects that are relevant to my assessment.
Filter: The task set at the beginning is filtering. Filtering requirements can be more extensive and complex, for example as a combination of several conditions in either OR or AND logic. A JOIN has filtering properties. Implementing multiple and variable conditions using JOINs should be more strenuous compared to being able to limit yourself to the WHERE part of a query. Can one imagine a FormFilter that is preferably implemented via JOINs?
More extensive tasks: In (my) practice, you also have to deal with data models, where you don't just have to consider one or two tables, but sometimes 5, 6, ... 8 tables, of which there may also be several instances of the same table. Additional JOIN operations can become an adventure. Subqueries help me to read and understand a complete query process from table data to the end result, because I have the complete processing in one view and in a context and can quickly recognize, for example, superfluous intermediate sorting and superfluous table fields that are carried along. Understanding also helps in developing and later maintaining the instruction.
Ensuring that a query can be updated is by no means a rare wish or requirement.
I often have to deal with non-simple queries. The longest statement in Jet was probably more than 1200 characters long (using short table aliases). A lot happens, but it doesn't have to result in a performance or stability problem.
I think you are very happy that I use your own example from Speed Comparison Tests - Optimise Queries, which you know very well.I challenge you to devise one or more subqueries that do EXACTLY the same task as a single well optimised query and run faster
In my own cursory testing, I find the following statement to be competitive:
SQL:
SELECT
Sub1.PupilID,
Sub1.Surname AS LastName,
Sub1.Forename AS FirstName,
Sub1.YearGroup AS YearGp,
Sub2.Code,
Sub2.CodeType,
Sub2.Merits,
Sub2.Demerits,
Sub2.Incidents
FROM
(
SELECT
P.PupilID,
P.Surname,
P.Forename,
P.YearGroup
FROM
PupilData AS P
WHERE
P.DateOfBirth BETWEEN #1/1/2005# AND #12/31/2005#
) AS Sub1
INNER JOIN
(
SELECT
R.PupilID,
R.Code,
FIRST(C.Description) AS CodeType,
FIRST(R.MeritPts) AS Merits,
FIRST(R.DeMeritPts) AS Demerits,
COUNT(*) AS Incidents
FROM
PRCodes AS C
INNER JOIN PRecords AS R
ON C.Code = R.Code
WHERE
R.DateOfIncident BETWEEN #1/1/2018# AND #12/30/2018#
GROUP BY
R.PupilID,
R.Code
) AS Sub2
ON Sub1.PupilID = Sub2.PupilID
ORDER BY
Sub1.Surname,
Sub1.ForenameThat sounds a bit provocative. By special request, I am adding a few comments that I have omitted so far because they could easily be perceived as criticism rather than advice.to benefit from your wisdom
I not only looked at the results, but also at the test environment.
Code:
'start timer
StartTime = TimeGetTime() 'time in milliseconds
For iCount = 1 To 3
DoCmd.OpenQuery strQuery
lngCount = DCount("*", strQuery)
DoCmd.Close acQuery, strQuery
Next
'stop timer
EndTime = TimeGetTime() 'time in millisecondsIn practice, it is unlikely that an identical query will be executed several times immediately. "Significant" differences in the absolute amount for each individual query are then presented somewhat differently.
In my own test, I would run different queries individually and alternately to reduce the influence of cache, and then repeat the entire run several times. Single query:
Code:
Set rs = db.Openrecordset("QueryName", dbOpenSnapshot)
rs.MoveLastWith a flagship database, I would also pay attention to the little things. The reader will surely want to copy correctly.
Index planning
PRCodes
Duplicate index on Code
PupilData
A composite index using Surname and Forename makes sense because of the sorting in the query. Index on Forename is not used in the given constellation.
PRecords
Duplicate index on PastoralRecordID. Single indexes on Code and PupilID duplicate because RI (foreign keys are automatically indexed when referential integrity is set to a relationship, but this is not easily visible). Composite index using PupilID and Code makes sense because of grouping in query.
Duplicate indexes bring no benefit. However, they still have to be managed and therefore have a braking effect on writing actions.
The composite indexes mentioned can have a direct effect on performance if the SQL optimizer cooperates. In a description of performance, one should not neglect this, as well as index use in general.
SQL:
GROUP BY
PupilData.PupilID,
PupilData.Surname,
PupilData.Forename,
PupilData.YearGroup,
PRecords.Code,
PRCodes.Description,
PRecords.MeritPts,
PRecords.DeMeritPts,
Year([DateOfBirth]),
Year([DateOfIncident]),
[Surname] & ", " & [Forename]A JOIN has a filtering function, but also a multiplying function. When several tables are joined, the contents of individual tables in the query are duplicated, and this is usually the first step in processing the query. In the query result, however, you no longer want to see duplicates, there is a "necessity" to group them (as far as possible).
The bottom line is that one can ask oneself how efficient it will be to first multiply content and thus also increase the number of data records in order to then reduce them again ... if you could leave content unique throughout.
I also look forward to feedback.
Last edited:


") just getting over man flu
just getting over man flu
