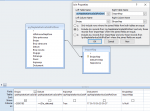
In the attachment I have put the query design. The qryNaplataKarticaSaIdPotDom alone runs just fine even tho the table has over 1m records. However, when I do a LEFT JOIN like in the attachment with this query and the table ImportNap, then it takes more than 3min for the query to load. When I remove the Is Null from the field BrojacNap the query loads quite fast, few seconds. But I need that Is Null criteria.
Brojac, Dokument and BrojacNap I have put indexes on, however no much help, if any.
Any ideas what could I change?
Thanks!")
Brojac, Dokument and BrojacNap I have put indexes on, however no much help, if any.
Any ideas what could I change?
Thanks!