isladogs
Access MVP / VIP
- Local time
- Today, 18:17
- Joined
- Jan 14, 2017
- Messages
- 19,550
Hi all
I updated my Mythbusters: WHERE vs HAVING thread yesterday
When I did so, @CJ_London reminded me of a previous request to test the following:
I must confess I'd never thought about comparing these before but did so this morning
I asked the following question both in the thread & in a PM to @CJ_London :
All those who responded tended to agree.... BUT the opposite was true ...
I did various tests on 2 different datasets and on each test (without exception), GROUP BY was slightly faster.
The differences were relatively small but they were consistent in every test
First of all, I tested my Postcodes dataset (2.6 million records):
In my first set of tests, I ran the following queries:
qryDistinct
qryGroupBy
Each gave exactly the same output of 12415 records.
All fields in the queries were indexed
I looped through each query 3 times and measured the total time in each case.
I repeated each test & calculated the averages:

I then filtered the data when running each query to see if that would change the results. Same outcome...

I then repeated the tests, but this time appended the query output into a temp table each time to ensure that the query had been loaded fully during the tests.
Same outcome ....

I ran JET ShowPlan on each of the queries. The results were almost identical:

Next I tried using a different dataset supplied by @CJ_London.
It was a smaller dataset of approx 150K records so I looped through each query 20 times.
This time, there were 2 non-indexed fields in the queries
Once again the two queries gave identical outputs = 8324 records
Did that affect the outcomes? NO

Next I ran Jet ShowPlan on each query. The execution plans were almost identical:

NOTE:
The 'by scanning' reference' indicates that Access had to scan the entire dataset in each case due to the inclusion of non-indexed fields
I can't upload my Postcodes dataset as the ACCDB file is about 1.6 GB
However, I will upload the example app with @CJ_London's dataset if he confirms its OK to do so
==========================================================================
For more info on Jet ShowPlan, see my article:

 www.isladogs.co.uk
www.isladogs.co.uk
Also see this excellent article by Mike Wolfe:

 nolongerset.com
nolongerset.com
I updated my Mythbusters: WHERE vs HAVING thread yesterday
Mythbusters - Speed Comparison Tests - Having vs Where
This is a follow up to a recent thread Desperate-Count Help Needed https://www.access-programmers.co.uk/forums/showpost.php?p=1597549&postcount=8 Part of this included discussion of the comparative efficiency of aggregate queries using WHERE with HAVING. I thought that Galaxiom explained this...
www.access-programmers.co.uk
When I did so, @CJ_London reminded me of a previous request to test the following:
We often see OP's using aggregate queries without any aggregation rather than SELECT DISTINCT - do you have an example to compare a SELECT DISTINCT v GROUP BY with perhaps a criteria or two?
I must confess I'd never thought about comparing these before but did so this morning
I asked the following question both in the thread & in a PM to @CJ_London :
Before I started, I had a gut feeling that SELECT DISTINCT would be slightly faster though I couldn't have given any meaningful reason for thatwhat are your predictions before I make the results public?
All those who responded tended to agree.... BUT the opposite was true ...
I did various tests on 2 different datasets and on each test (without exception), GROUP BY was slightly faster.
The differences were relatively small but they were consistent in every test
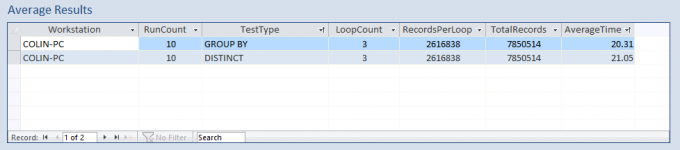
First of all, I tested my Postcodes dataset (2.6 million records):
In my first set of tests, I ran the following queries:
qryDistinct
Code:
SELECT DISTINCT Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector
FROM Postcodes;qryGroupBy
Code:
SELECT Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector
FROM Postcodes
GROUP BY Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector;Each gave exactly the same output of 12415 records.
All fields in the queries were indexed
I looped through each query 3 times and measured the total time in each case.
I repeated each test & calculated the averages:
I then filtered the data when running each query to see if that would change the results. Same outcome...
I then repeated the tests, but this time appended the query output into a temp table each time to ensure that the query had been loaded fully during the tests.
Same outcome ....
I ran JET ShowPlan on each of the queries. The results were almost identical:
Next I tried using a different dataset supplied by @CJ_London.
It was a smaller dataset of approx 150K records so I looped through each query 20 times.
This time, there were 2 non-indexed fields in the queries
Once again the two queries gave identical outputs = 8324 records
Did that affect the outcomes? NO
Next I ran Jet ShowPlan on each query. The execution plans were almost identical:
NOTE:
The 'by scanning' reference' indicates that Access had to scan the entire dataset in each case due to the inclusion of non-indexed fields
I can't upload my Postcodes dataset as the ACCDB file is about 1.6 GB
However, I will upload the example app with @CJ_London's dataset if he confirms its OK to do so
==========================================================================
For more info on Jet ShowPlan, see my article:
Show Plan - Go Faster
Use Jet ShowPlan to view the execution plan of Access queries. This can help optimise query execution
www.isladogs.co.uk
Also see this excellent article by Mike Wolfe:
JetShowPlan: A Primer
You may be familiar with JetShowPlan, but I guarantee you've never read an article about it quite like this one.
Attachments
Last edited:
")





